

My quantum circuit simulator Quirk is one of those projects that I keep coming back to. For years, I only touched it intermittently. Then, over the past few months, the work kinda took off and I've been stuck in a cycle of "Okay, with that release I think I can set it down now." followed by literally opening 10 issues the next day.
Last month, and this month I suppose, one of those issues was "performance". So I thought it would be interesting to go back and see how Quirk's performance has changed over time, since the beginning. There's probably some lessons to be had (... not original lessons, but lessons nonetheless).
What I'm Measuring
Quirk doesn't do any fancy algorithmic tricks for computing particular circuits faster. The circuits that people put together with a drag-and-drop GUI just aren't large enough to justify that kind of thing. This makes Quirk's performance essentially circuit-agnostic: the types of gates you use doesn't affect performance much. What matters is how many gates you use, and of course how many wires are present (that's where the exponential costs are).
Circuit agnosticism is great for the purposes of this post, because it makes comparing versions easier. Profiling performance against a single straightforward circuit will tell us basically the whole story.
The choice of circuit to use is mostly arbitrary, but there are a few constraints. The circuit can't be too small, because the interesting question is what blows up as circuits get larger. We don't want to measure the constant-time noise that swamps out the cost of smaller circuits. The circuit also can't be too big, because that would cause unmeasurably bad performance and even OOM errors in the really old versions. Finally, we'll avoid putting inline displays in the circuit, despite that being one of Quirk's most important features, because the non-trivial displays were only added recently.
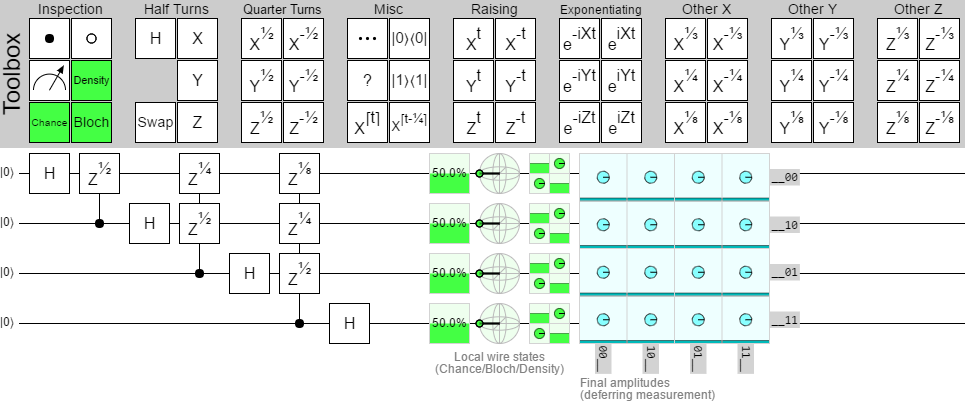
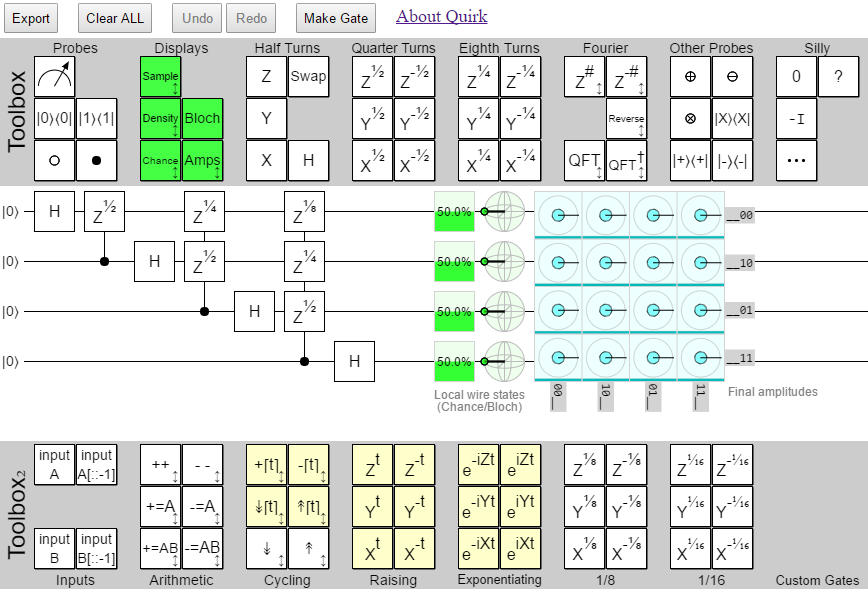
With those constraints in mind, I decided to go with a 10-qubit quantum fourier transform without the bit reversal step. It has enough gates and wires to be interesting, but not so many that I expect to break the older versions. Here's a diagram of the circuit:
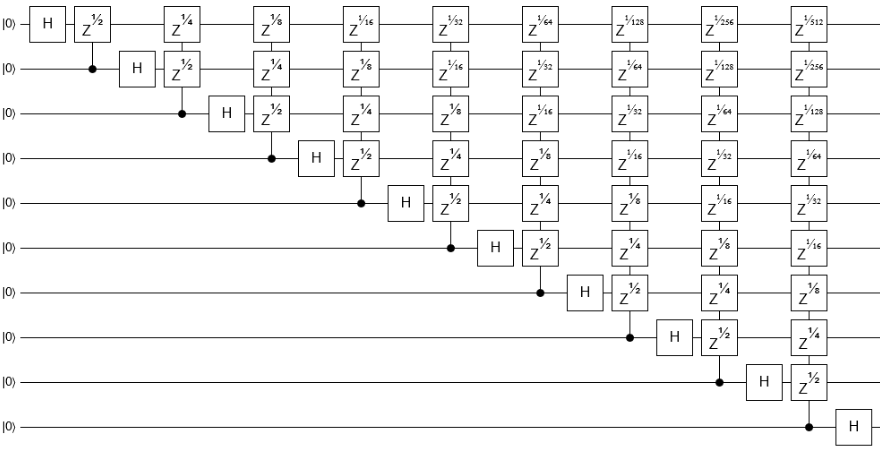
Note that I want to learn about the performance in general on circuits of this size. So I won't be using the specialized QFT or phase gradient gates available in later versions, even though those gates would speed up this particular circuit.
All of my testing will be done in Chrome v54. The machine I'll be testing with is an HP Spectre x360. The CPU is an i7-5500U. The GPU is an integrated HD5500. Testing in other browsers and with other machines is of course a great idea, but just doing the one was already quite a lot of work.
What I'll actually be doing, as the profiler runs, is dragging one of the circuit's gates around. This forces Quirk to constantly react, simulate, and draw. Then I'll pick out a representative frame, made up of "react, simulate, draw" parts, show a screenshot, and discuss a bit.
Enough details, let's travel through time.
Pre-history
This is a random widget I included in a post near the start of 2014. Quirk grew out of this widget. Unfortunately, it can't do a 10-qubit QFT... I only included it here out of a misguided desire for completeness.
December 2014
No undo, no bookmarking the state, no build step, no webgl, fuzzy lines because they're off by a half-pixel, weird gate notation, state display outside of the circuit... yeah, that definitely takes me back. (On the other hand, it's only 2500 lines.)
This version doesn't give the user control over the number of wires, so I had to tweak the code to set the number of wires to 10. I immediately regretted that as soon I started building up the circuit. The level of slow was unbearable (so much for that "can't be too big" constraint on the circuit). So I dropped the number of wires to 8.
I entered an 8-qubit QFT, started Chrome's profiler, grabbed one of the gates, dragged it around like crazy, and watched my laptop chug away trying to keep up.
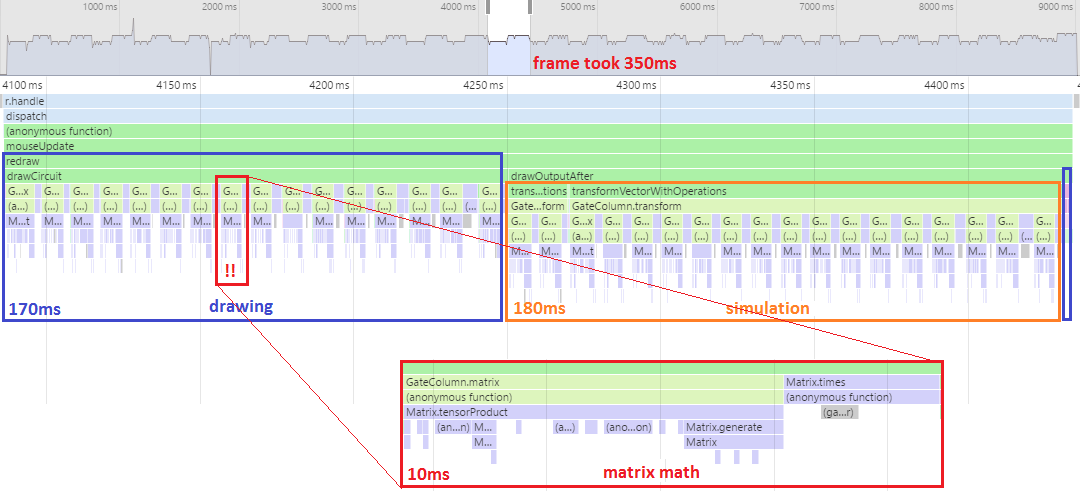
Frame time: 1.5 seconds (after adjusting for the 2-qubit handicap)
One look at the flame graph tells me what prevented me from doing a 10-qubit circuit (looking at flame graphs tends to do useful things like that, they're amazing).
This old version of Quirk is tensoring all of the gates in a column together into a single giant matrix, then smashing that matrix into the state vector. That's simple, but it's also really really inefficient. The matrices defined by single-qubit gates are sparse: you can apply them with a single scan over the state vector, in linear time. The big-fucking-matrix approach, on the other hand, does quadratic amounts of work. Which is kind of a big deal when $n=2^{10}$; literally a thousand times more expensive.
Also, these were not lightweight highly optimized matrices. They were arrays of arrays of instances of a complex number class in javascript. We're talking millions of allocations done to apply each column of gates. That poor garbage collector! No wonder the performance is so bad.
December 2015
Apparently I hated color in 2015. Could the screenshot BE more drab?
(Keep in mind that, although the version context screenshots I'm showing have Quirk containing 4-qubit circuits, that's only for screenshot-size reasons. I'll always be profiling the 10-qubit circuit unless noted otherwise.)
Intermittently over the course of 2015, I modified Quirk to do its simulation with webgl instead of in javascript. I also rewrote it to use ES6, translated down to ES5 by Traceur. The matrix functions are still horrendously inefficient, but they're not used much anymore. The improvement is quite noticeable:
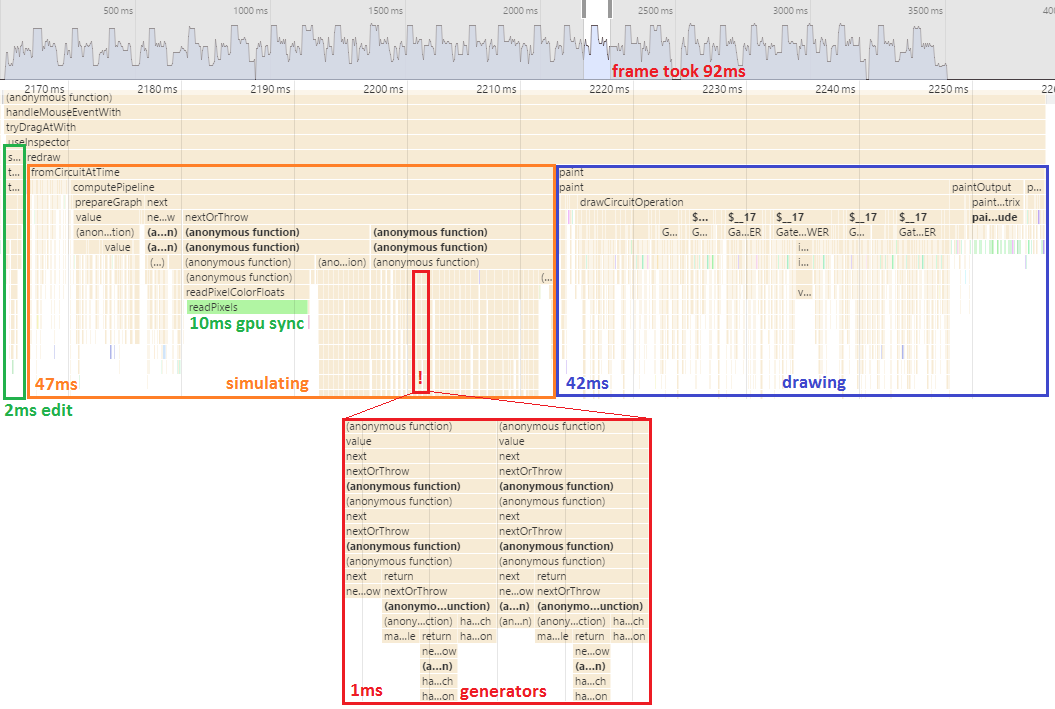
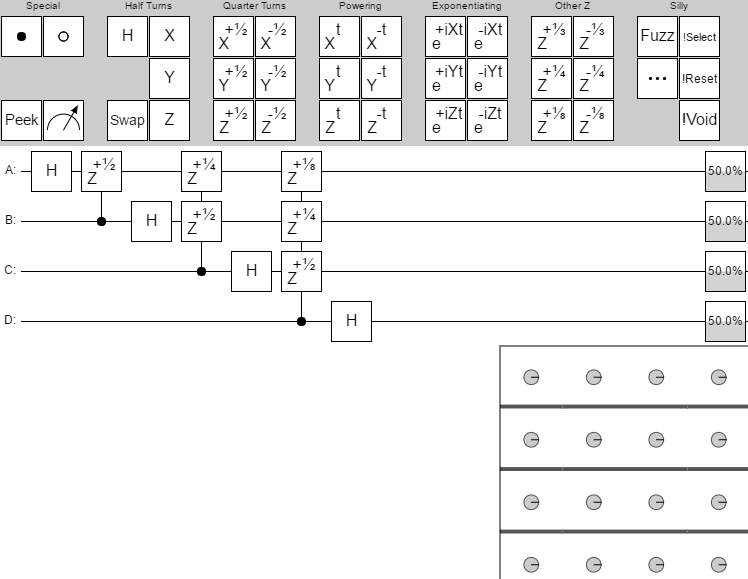
Frame time: 92ms.
An order of magnitude better than the previous version (accounting for the handicap). GPUs are amazing.
The big performance offender now is these deep spikes of anonymous functions. The root problem is that I like to write code that's very LINQ-y: layering lots of transformations, filters, grouping, and aggregation over iterables. I like it so much that I wrote lots of generator-heavy methods just for that purpose. But Traceur doesn't do a good job of translating generators into efficient ES5 code, and so here we are.
Another big problem here, exacerbated by the generator issue, is the 'pipeline' system the simulation code is using. Instead of just applying shaders, I was building up a graph of which shaders needed which outputs then interpreting over the graph. Sometimes that approach to a computation is useful, but for Quirk it was just actively unhelpful and costly. It's definitely a mistake I wish I could take back.
March 2016
Glorious color! We jumped from total desaturation to basically what Quirk looks like nowadays. There's lots of minor details missing (e.g. no shadows under the toolbox gates, no details when hovering over displays, always-present 'deferring measurement' label), but it's recognizably Quirk. Very appropriate, since before this point I hadn't named it.
Amongst many other changes, the pipeline code has been taken out and shot. Profiler says... good decision!
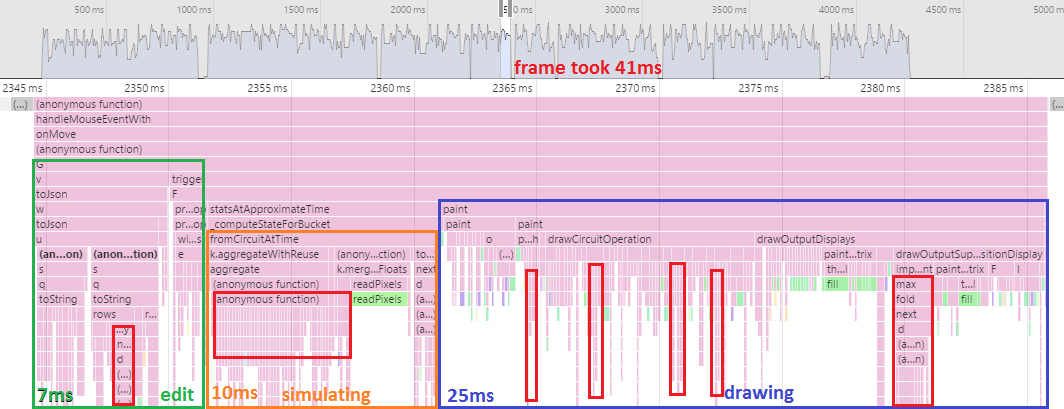
Frame time: 41ms.
We halved the frame time. Interestingly, the drawing cost also dropped significantly. I think this might be from switching how I made text fit in the gate boxes: instead of searching for a font-size that resulted in the text not poking out, I used the initial text-width measurement to choose a scale factor to apply to the canvas drawing context before printing.
It's also interesting that the edit time of the circuit has shot up. Something to do with the JSON serialization, done as part of creating a bookmarkable URL for the circuit.
The costly generator code is still rearing its head (I outlined some of it in red), but unfortunately that's not going to be fixed anytime soon. Actually, we're going to be heading the wrong way performance-wise for a bit.
April 2016
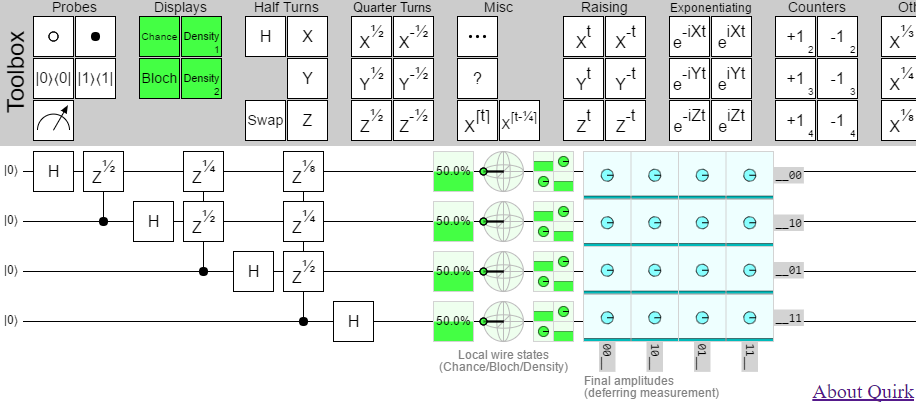
Multi-wire gates in the toolbox! But I had trouble thinking of a discoverable-on-mobile way for users to resize gates, so instead of having single resizable gates the toolbox is exploding with size variants.
April was an "add a feature" month, with no big changes that should have affected performance. There were some optimizations of the matrix code, but only for keeping the tests running quickly when comparing shader effects against a matrix. The matrix code isn't used much during simulation or drawing, so you wouldn't see any gains at runtime.
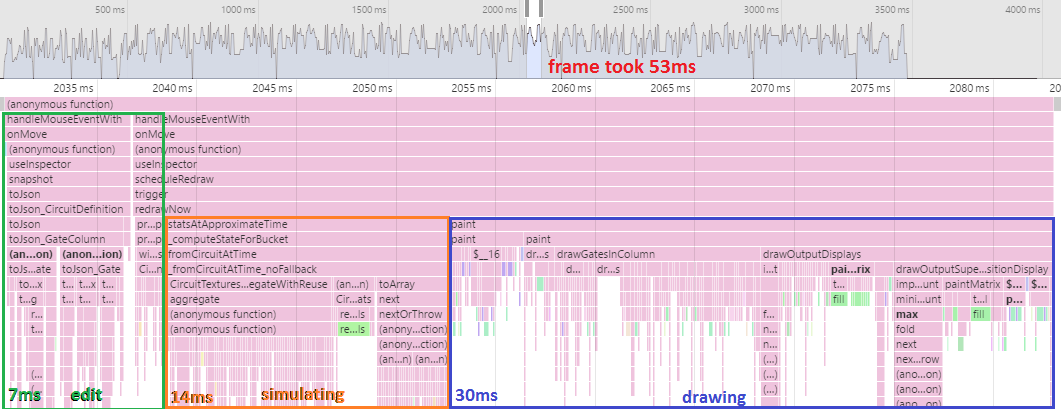
Frame time: 53ms.
Hahaha, did you laugh, when I said the changes shouldn't affect performance, without any justification? That's just not how performance works. Performance gets worse by default. You have to actively put work into keeping it good. 10ms penalty.
May 2016
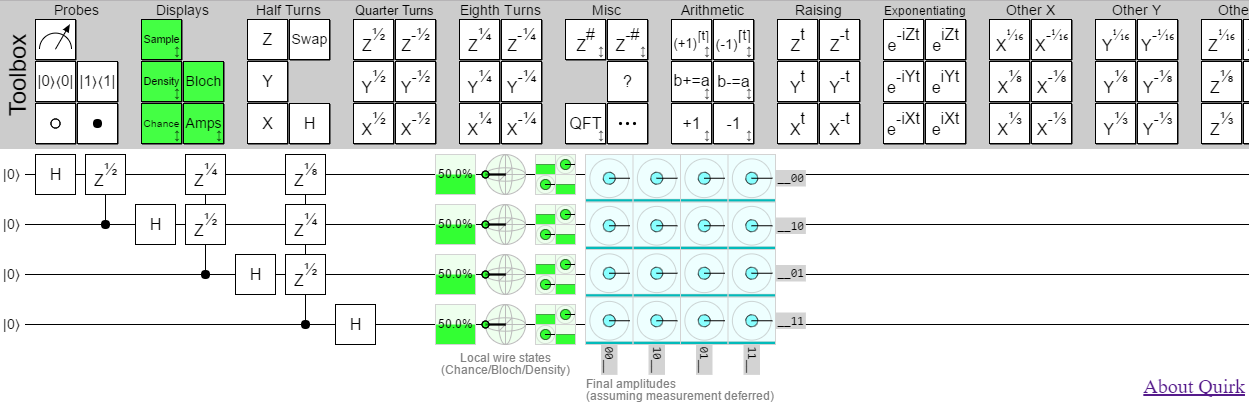
The month of four releases. A lot of stuff was added: three new displays, Fourier and arithmetic gates, the ability to resize gates... that's way more than a month's work for an intermittent weekend project. This is the first version I called attention to by putting it on social media.
Lots of new features, but no focus on measuring or improving performance. So...
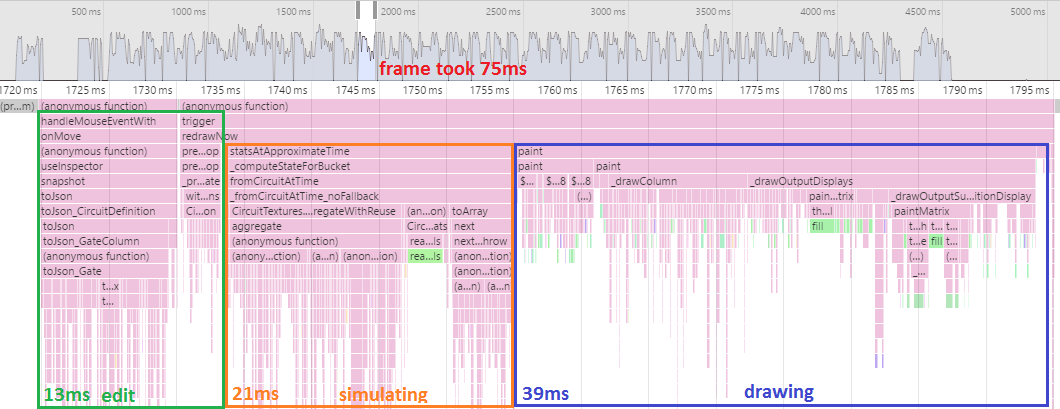
Frame time: 75ms.
The performance regression continues. For context, note that in the game industry anything over 16 milliseconds gets laughed out of the room. 60fps or bust. At 75ms per frame, Quirk can't even hit 15fps.
(Weirdly, the flame graph looks quite similar to the previous month's, just with everything taking a bit longer. At first I thought my laptop had been busy or something and spoiled the run, but re-running it later gave similar results.)
June 2016
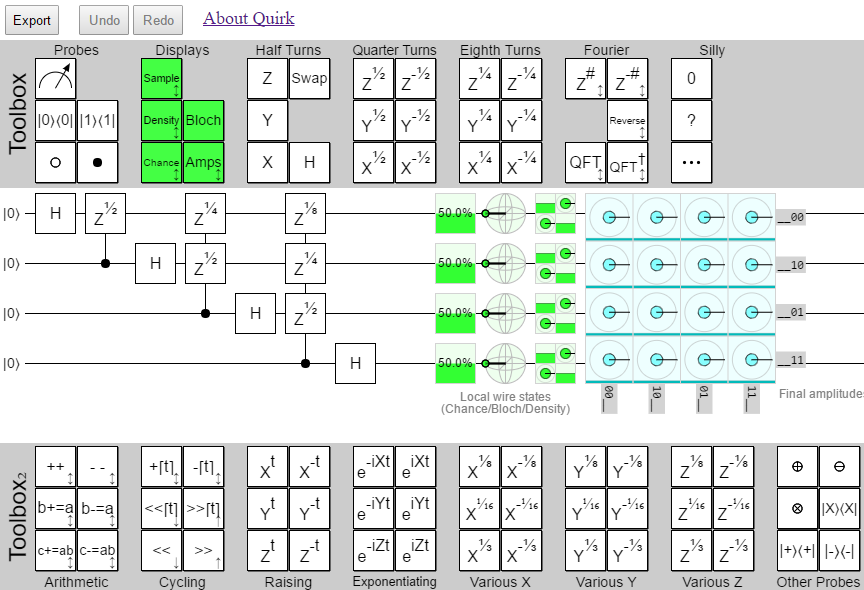
Second toolbox has arrived, with plenty of gates in tow. Also, export/undo/redo buttons.
Another feature month, and you know what that means.
Frame time: 53ms.
Wait, what? It got better? Even though the edit cost hit slow generators and went up 50%? Wat?
After some investigation, I think the simulation cost going back to 15ms is because of code to compute the density matrices of pairs of qubits. It was added in May, but not really used by anything, and dropped in June.
As for the same performance-loss-and-recovery happening in the draw code... I think this was the month where I started batching stroke/fill calls to the canvas API.
September 2016
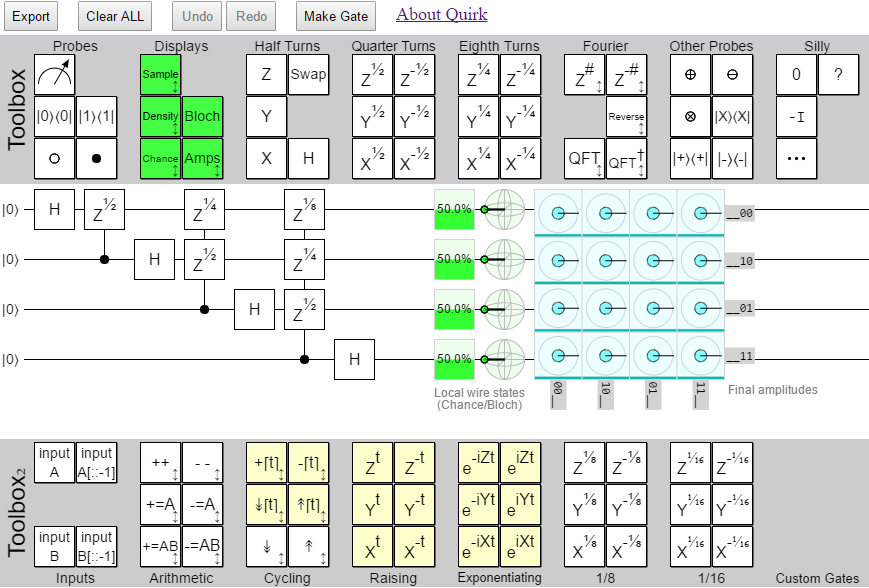
Dynamic gates with yellow highlight. Arithmetic gates with independent inputs. One fewer default output display. But, most importantly, a 'Make Gate' button. Custom gates at last!
September's changes touched a lot of the circuit definition/simulation code. Gates that use an input need to be paired up with the corresponding input gate, amongst other things. Big risk of performance regressions.
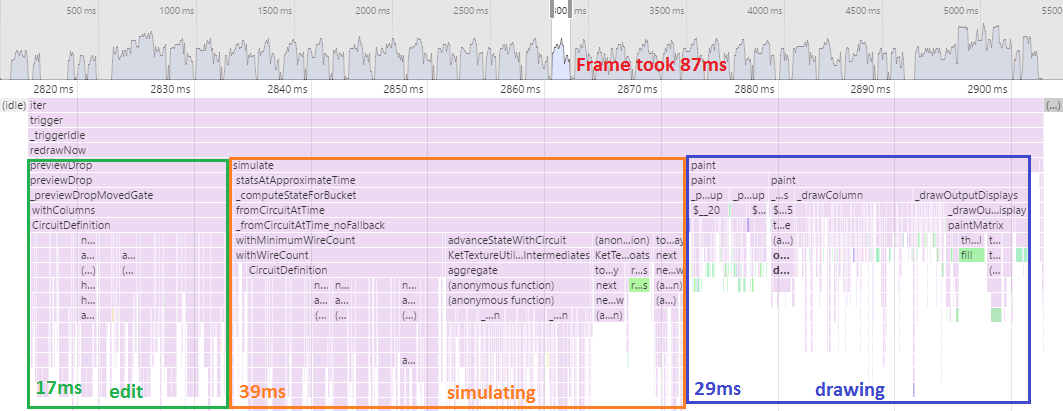
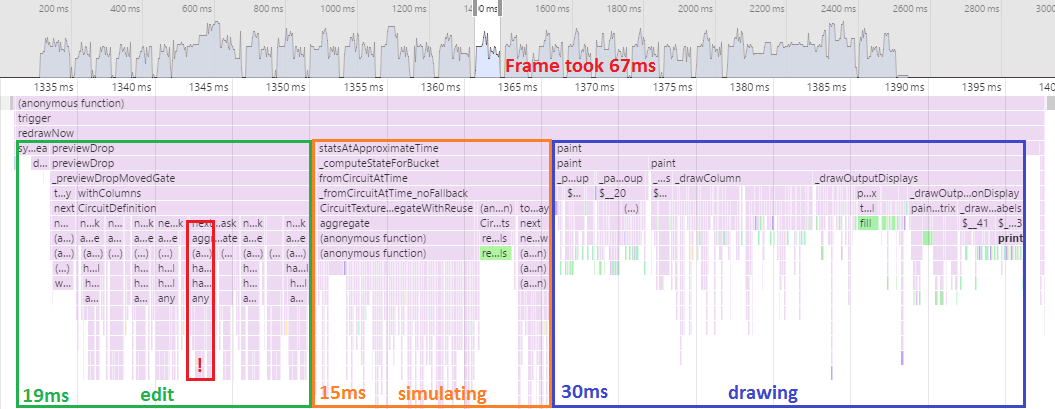
Frame time: 87ms.
Ouch, that's a big hit. Apparently I severely hurt the code computing circuit properties like "does this gate have a problem requiring that it be disabled?". The cost from generators is really getting out of hand.
October 2016
Looks the same. All the changes were under the hood. iPhone compatibility required working with byte textures, which caused huge shader rewrites.
October touched a lot of shader code, which is performance-sensitive. But the regression from the previous month was bad enough that I had actually noticed it by eye (and I have a terrible eye for frame rate issues). So the other big change in October was a focus on improving performance.
Meaning...
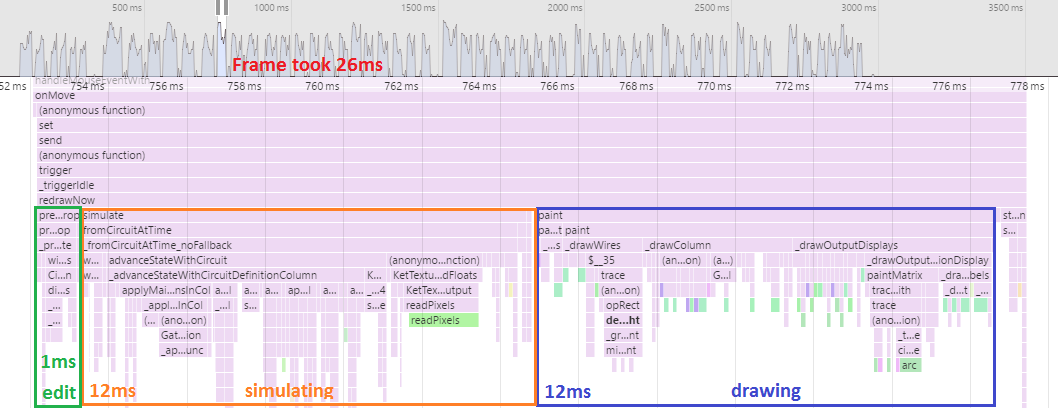
Frame time: 26ms.
This is what happens when you let things regress for awhile, then open up a profiler and get serious. Immediate massive improvement. (26 is nothing to brag about, but at least it's not frickin 87.)
The profiler told me the generators were slow, and where they were slowest.
I switched to for loops where appropriate.
The profiler told me that drawing the toolboxes was taking 10 milliseconds.
I switched to drawing them once and caching the image data.
The profiler told me a lot of useful things.
The profiler is still telling me a lot of useful things.
Future
I added perf tests as a way to prevent future regressions in performance. But that's not enough.
(Does anyone know how to get travis-ci, or another free continuous integration service, to run WebGL code? Add an answer to this stackoverflow question.)
Even without regressions, editing 16 qubit circuits (the maximum size that Quirk permits) feels slow and clunky. It always has. Another month of performance gains is required. Based on profiling a 16-qubit circuit, the big problem is the drawing code:
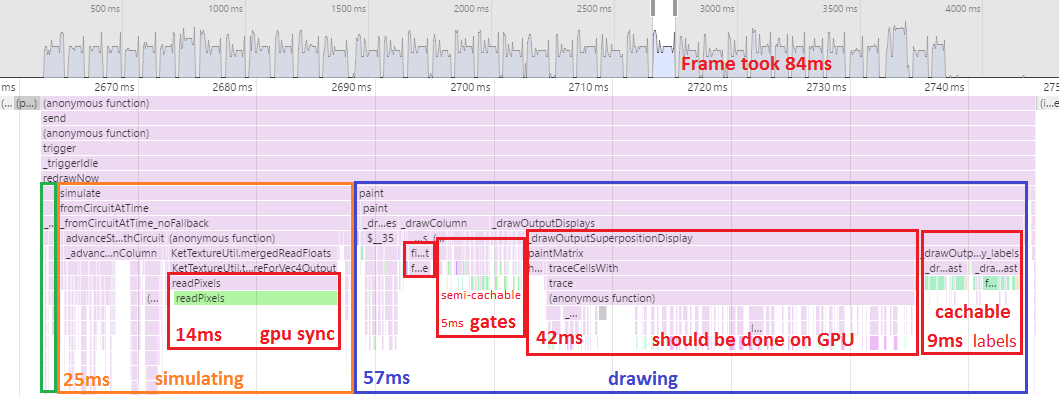
If I want to get under 30ms per frame for 16-qubit circuits, I can't draw the huge amplitude displays with canvas commands anymore. I have to do it with the GPU. Also I need to do more caching of repeated visual elements.
More long term, if I want to even think about getting below 16ms per frame, I need to avoid the cost of syncing up with the GPU.
That would require quite a lot of re-architecting, because it means I can't call readPixels and all displays would have to be drawn GPU-side (including their text-heavy tooltips).
Also I'd need to learn how to properly profile and optimize shaders.
It's a lot of work to do for a toy quantum circuit simulator. But, somehow, it's the toy projects that are the most engaging. So who knows.
Summary
- Don't write horribly inefficient matrix code that does millions of allocations.
- Don't use ES6-to-ES5 generators on hot paths.
- Don't forget to track performance when adding features.
- Do use the GPU.
- Do use Chrome's profiler.
- Do cache image data of elements always drawn the same way.
- There's still a long way to go.
